컴포넌트 결합
- ADP: 의존성 비순환 원칙 (Acyclick Dependencies Principle)
- SDP: 안정된 의존성 원칙(Stable Dependencies Principle)
- SAP: 안정된 추상화 원칙(Stable Abstractions Principle)
SAP
- 안정된 추상화 원칙(Stable Abstractions Principle)
컴포넌트는 안정된 정도만큼만 추상화되어야 한다.
고수준 정책을 어디에 위치시켜야 하는가?
- 시스템에는 자주 변경해서는 절대로 안 되는 소프트웨어도 있다. 고수준 아키텍처나 정책 결정과 관련된 소프트웨어가 그 예다.
- 업무 로직이나 아키텍처와 관련된 결정에는 변동성이 없기를 기대한다. 따라서 시스템에서 고수준 정책을 캡슐화하는 소프트웨어는 반드시 안정된 컴포넌트(I = 0)에 위치해야 한다. 불안정한 컴포넌트(I = 1)는 반드시 변동성이 큰 소프트웨어, 즉 쉽고 빠르게 변경할 수 있는 소프트웨어만을 포함해야 한다.
- 고수준 정책을 안정된 컴포넌트에 위치시키면, 그 정책을 포함하는 소스 코드는 수정하기가 어려워진다. 이로 인해 시스템 전체 아키텍처가 유연성을 잃는다. 컴포넌트가 최고로 안정된 상태이면서도(I = 0) 동시에 변경에 충분히 대응할 수 있을 정도로 유연하게 만들 수 있는 방법은 개방 폐쇄 원칙(OCP)에서 찾을 수 있다.
안정된 추상화 원칙
- 안정된 추상화 원칙(SAP)은 안정성(stability)과 추상화 정도(abstractness) 사이의 관계를 정의한다.
- 안정된 컴포넌트는 추상 컴포넌트여야 한다.
- 인터페이스와 추상 클래스로 구성되어 쉽게 확장할 수 있어야 한다.
- 불안정한 컴포넌트는 반드시 구체 컴포넌트여야 한다.
- 컴포넌트가 불안정하으므로 컴포넌트 내부의 구체적인 코드를 쉽게 변경할 수 있어야 하기 때문.
- 안정된 컴포넌트가 확장이 가능해지면 유연성을 얻게 되고 아키텍처를 과도하게 제약하지 않게 된다.
- _SAP_와 _SDP_를 결합하면 컴포넌트에 대한 _DIP_나 마찬가지가 된다.
- _SDP_에서는 의존성이 반드시 안정성의 방향으로 향해야 한다고 말한다.
- _SAP_에서는 안정성이 결국 추상화를 의미한다고 말한다.
- 따라서 의존성은 추상화의 방향으로 향하게 된다.
추상화 정도 측정하기
- A 지표는 컴포넌트의 추상황 정도를 측정한 값이다.
- Nc: 컴포넌트의 클래스 개수
- Na: 컴포넌트의 추상 클래스와 인터페이스 개수
- A: 추상화 정도.
- A = \text{Na}\div\text{Nc}
- A 지표는 [0, 1] 범위를 갖는다.
- A 가 0이면 컴포넌트에 추상 클래스가 하나도 없다는 뜻.
- A가 1이면 컴포넌트는 오로지 추상 클래스만을 포함한다는 뜻이다.
주계열
- 주계열이란? 천문학 용어로, 관측된 모든 별 중의 90%가 표시되어 있는 좁은 띠를 말함
- 불안정성(I)과 추상화 정도(A) 사이의 관계를 정의해야 할 때가 왔다.[그림 10-1. I/A 그래프]

- 그림 10-1을 보면 최고로 안정적이며 추상화된 컴포넌트는 좌측 상단인 (0, 1)에 위치한다.
- 최고로 불안정하며 구체화된 컴포넌트는 우측 하단인 (1, 0)에 위치한다.
- 모든 컴포넌트가 이 두 지점에 위치하는 것은 아닌데, 대체로 컴포넌트는 추상화와 안정화의 정도가 다양하기 때문이다.

[그림 10-2. 배재구역(Zone of Exclusion)]- 대부분의 컴포넌트는 주계열(The Main Sequence)에 존재해야 하며 배재구역(쓸모없는 구역, 고통의 구역)에 존재하는 컴포넌트를 찾는 방식으로 추론할 수 있다.
고통의 구역(Zone of Pain)
- 이지역의 컴포넌트는 매우 안정적이며 구체적이다.
- 추상적이지 않으므로 확장할 수 없고, 안정적이므로 변경하기도 상당히 어렵다.
- 이 지역의 소프트웨어로는 구체적인 유틸리티 라이브러리를 들 수 있다. 이러한 라이브러리는 I 지표가 0일지라도, 실제로는 변경성이 거의 없다. 예를 들어 String 컴포넌트를 생각해보면 구체 클래스이지만 굉장히 광범위하게 사용되기 때문에 이 컴포넌트는 수정 할 수 없다.
- 변동성이 없는 컴포넌트는 (0, 0) 구역에 위치했더라도 해롭지 않다.
- 또 다른 예로, 소프트웨어 엔티티는 고통의 구역에 위치하곤 한다. 데이터베이스 스키마가 한 예다. 데이터 베이스 스키마가 변경되면 대체로 고통을 수반한다.
쓸모없는 구역(Zone of Uselessness)
- (1, 1) 주변의 컴포넌트를 생각해 보자.
- 여기 위치한 컴포넌트는 최고로 추상적이지만, 누구도 그 컴포넌트에 의존하지 않는다. 따라서 이 영역은 쓸모없는 구역(The Zone of Uselessness)라고 불린다.
- 이 영역에 존재하는 소프트웨어 엔티티는 폐기물과도 같다.
주계열과의 거리
- 세 번째 지표가 도출된다. 컴포넌트가 주계열 바로 위에, 또는 가까이 있는 것이 바람직하다면, 이 같은 이상적인 상태로부터 컴포넌트가 얼마나 멀리 떨어져 있는지 측정하는 지표를 만들어 볼 수 있다.
- D = \left\vert A+I-1\right\vert
- 이 지표의 유효범위는 [0, 1]이다.
- D가 0이면 주계열 바로 위에 위치한다는 뜻이며, 1이면 주계열로부터 가장 멀리 위치한다는 뜻이다.
- 설계를 통계적으로 분석하는 일 또한 가능해진다.
- D지표의 평균과 분산을 구한다. 주 계열에 일치하도록 설계되었다면 평균과 분산은 0에 가까워진다. 분산을 통해 다른 컴포넌트에 비해 '극히 예외적인'컴포넌트를 식별할 수 있다.
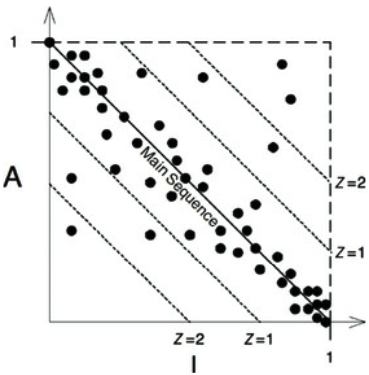
[그림 10-3. 컴포넌트 산점도]
- 그림 10-3을 통해 이상한 컴포넌트를 좀 더 면밀히 검토해 볼 가치가 있다.
- 이들은 자신에게 의존하는 컴포넌트가 거의 없는데도 너무 추상적이거나, 자신에게 의존하는 컴포넌트가 많은데도 너무 구체적인 것이다.
결론
- 의존성 관리 지표는 설계의 의존성과 추상화 정도가 내가 '훌륭한' 패턴이라고 생각하는 수준에 얼마나 잘 부합하는지를 측정한다.
- 좋은 의존성도 있지만 좋지 않은 의존성도 있다.
- 그러나 지표는 신이 아니다. 지표는 그저 임의로 결정된 표준을 기초로 한 측정값에 지나지 않는다. 지표를 통해 무언가 유용한 것을 찾을 수 있다면 그걸로 족하다.
클린 아키첵처 전체 보기
클린 아키텍처란? https://blog.kjslab.com/199
클린 아키텍처 - 설계원칙 - SRP https://blog.kjslab.com/200
클린 아키텍처 - 설계원칙 - OCP https://blog.kjslab.com/201
클린 아키텍처 - 설계원칙 - LSP https://blog.kjslab.com/202
클린 아키텍처 - 설계원칙 - ISP https://blog.kjslab.com/203
클린 아키텍처 - 설계원칙 - DIP & SOLID 요약 https://blog.kjslab.com/204
클린 아키텍처 - 컴포넌트 https://blog.kjslab.com/205
클린 아키텍처 - 컴포넌트 결합 - ADP https://blog.kjslab.com/206
클린 아키텍처 - 컴포넌트 결합 - SDP https://blog.kjslab.com/207
클린 아키텍처 - 컴포넌트 결합 - SAP & 결론 https://blog.kjslab.com/208
'아키텍처 > 클린 아키텍처' 카테고리의 다른 글
| 클린 아키텍처 - 컴포넌트 결합 - SDP (12) | 2023.02.11 |
|---|---|
| 클린 아키텍처 - 설계원칙 - SRP (2) | 2023.02.11 |
| 클린 아키텍처 - 컴포넌트 (12) | 2023.02.11 |
| 클린 아키텍처란? (2) | 2023.02.11 |
| 클린 아키텍처 - 설계원칙 - LSP (2) | 2023.02.11 |




댓글